§A. Breaking News:
Today in Science Magazine, a major new article from IBM Research introducing a new brain-inspired, silicon-optimized chip architecture suitable for neural inference. The chip, NorthPole, is the result of nearly two decades of work by scientists (see illustration in §O below) at IBM Research and has been an outgrowth of a 14 year partnership with United States Department of Defense (Defense Advanced Research Projects Agency (DARPA), Office of the Under Secretary of Defense for Research and Engineering, and Air Force Research Laboratory). NorthPole, implemented using a 12-nm process on-shore in US, outperforms all of the existing specialized chips for running neural networks on ResNet50 and Yolov4, even those using more advanced technology processes. Additional results on BERT-base were presented at Hot Chips Symposium.
§B. For more information:
- Science paper (can be downloaded from this website only): https://www.science.org/stoken/author-tokens/ST-1491/full
- Science perspective (paywall): https://www.science.org/doi/full/10.1126/science.adk6874
- IBM Research blog
- LinkedIn Post
- HotChips video (paywall)
- HotChips slides (paywall)
§C. Challenge faced by computer industry:
Computing, since its inception, has been processor-centric, with memory separated from compute. See, for example, the Fig 1(A) below. This separation leads to increased data movement leading to significant energy-consumption. This separation, known as the von Neumann bottleneck, leads to bandwidth limitation, which, in turn, limits the amount of on-chip compute and compute utilization.
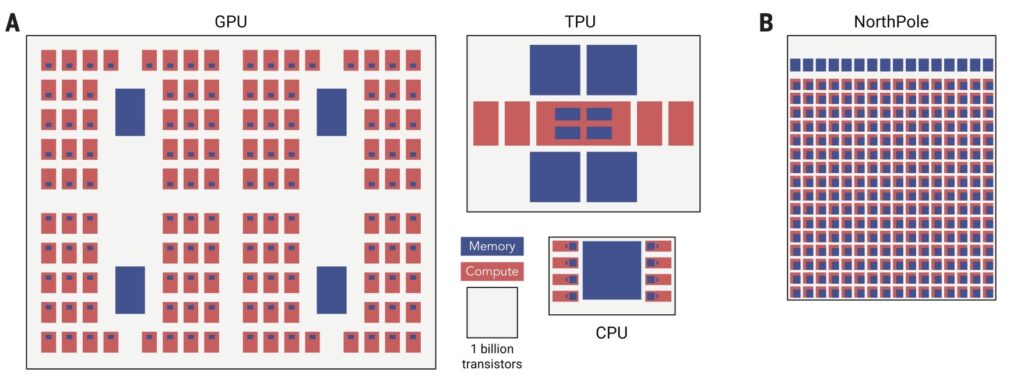
Fig. 1. Contemporary architectures (left), NorthPole (right).
The brain is vastly more energy-efficient than modern computers, in part because it stores memory with compute in every neuron, see, for example, Fig. 2 (https://www.pnas.org/doi/10.1073/pnas.1008054107).
NorthPole intertwines compute and processing on a single chip and has no off-chip memory, no centralized memory, and, therefore, mitigates the von Neumann bottleneck. This has the potential to enable the computer industry to overcome some major challenges, including the amount of energy and the amount of sheer processing that are required to run many deep neural networks. This is important because the capital and operating cost of AI is becoming unsustainable, and, in many applications, the response time of AI is too slow.
Because physics (silicon scaling) is delivering progressively slower gains, therefore, looking to mathematics (architecture) is a way to profoundly shift the trajectory of energy consumption. In this vein, NorthPole’s breakthrough is entirely architectural — it uses a novel brain-inspired and silicon-optimized architecture.

Fig. 3A. Photograph of the entire NorthPole die.
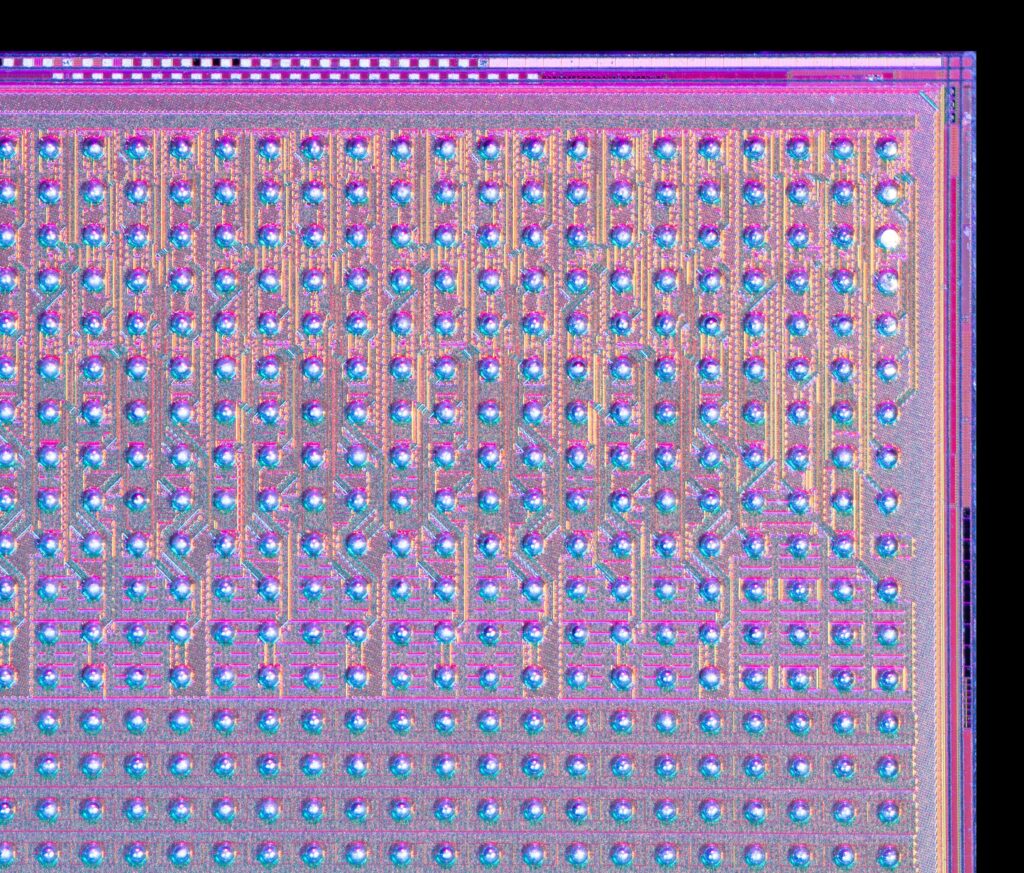
Fig. 3B. Photograph of a corner of the NorthPole die at higher magnification, using colored lighting to highlight visible structure.
§D. Why is this important:
On the x-axis below, we plot energy efficiency in terms of frames per second (FPS) per watt. Higher energy-efficiency means a lower operating cost to run an AI application. On the y-axis below, we plot space-efficiency in terms of FPS per billion transistors. Higher space-efficiency means lower capital cost to manufacture AI hardware. By using number of transistors as a metrics enables comparing different integrated circuits implemented in different technology processes.
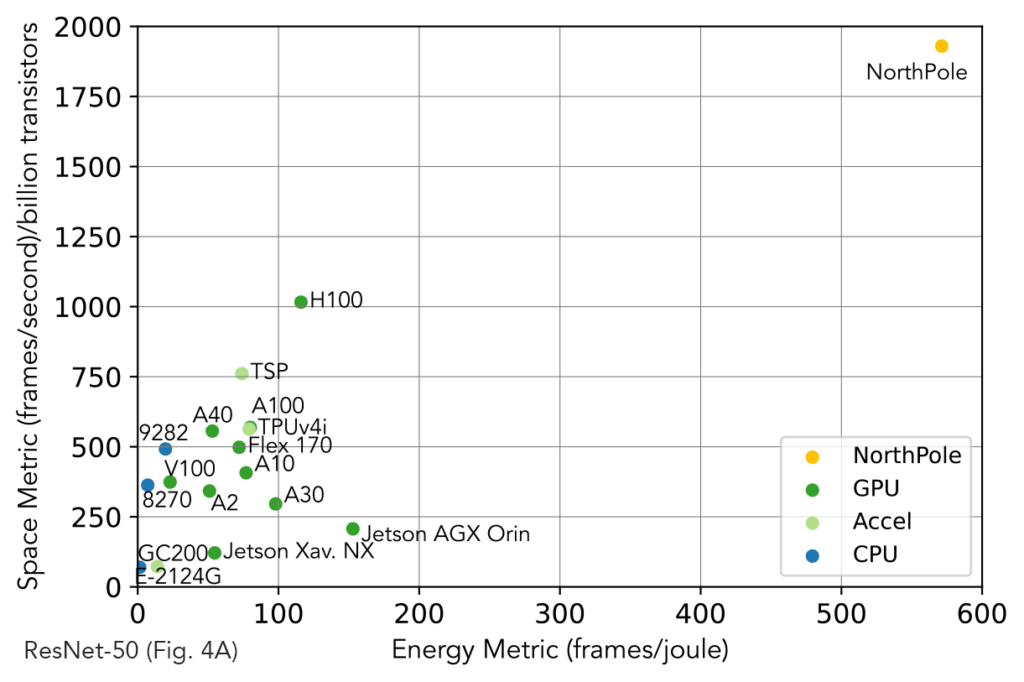
Fig. 4. NorthPole’s space metric (FPS per billion transistors) and energy metric (frames per joule, equal to FPS per watt) exceed those of contemporary GPUs, CPUs, and accelerators (Accel).
Note that NorthPole is in 12nm technology, whereas the leading contemporary architecture is in 4nm technology. Therefore, architecture trumps Moore’s law.
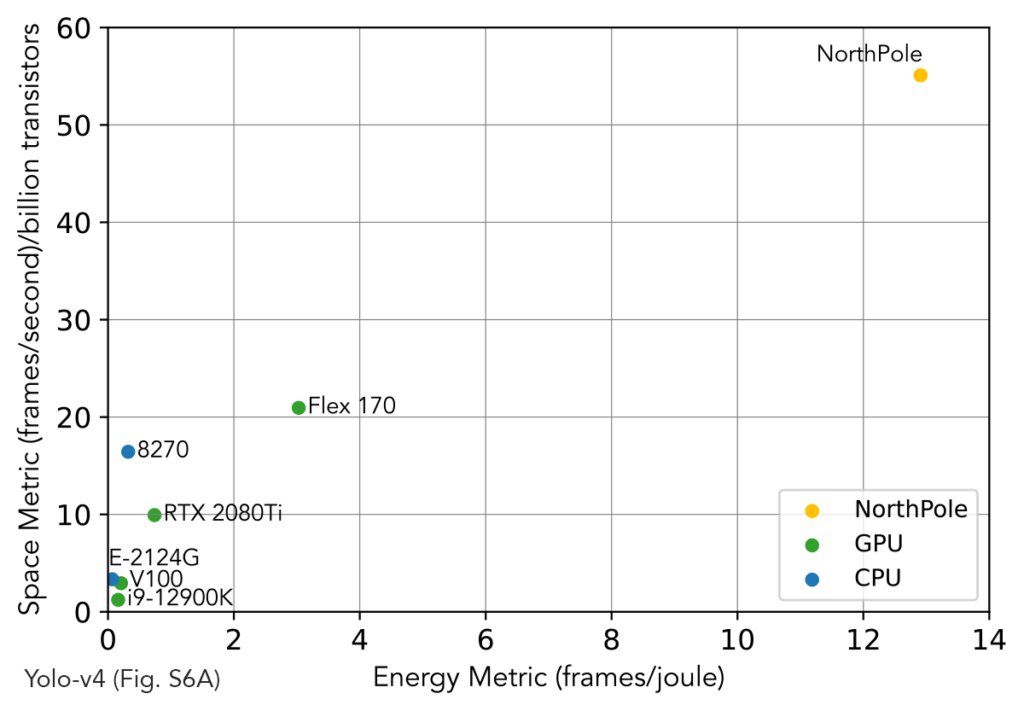
Fig. 5. NorthPole space metric (FPS/(billion transistors))and energy metric (frames/joule = FPS/W) exceed contemporary GPUs, CPUs, and accelerators (“Accel” in figure legend).
Fig. 6. NorthPole space metric (FPS/(billion transistors))and energy metric (frames/joule = FPS/W) exceed contemporary GPUs and accelerators (“Accel” in figure legend). This result was presented at HotChips 2023 conference.
Please note that NorthPole chip, software, systems are research prototypes, in IBM Research, and that NorthPole is designed for inference (not training). Also, please note that, although, by necessity, an implementation of the underlying NorthPole architecture is compared to specific integrated circuits, the main point is that, for neural inference, a brain-inspired architecture optimized for silicon points to a better future direction than the von Neumann architecture.
§E. HotChips Video:
On August 29, 2023, I gave a 20 minute talk on NorthPole at the HotChips Conference. The video will be publicly available in ~3 months. However, if you cannot wait, HotChips has “set up a post conference store where you can purchase access to the conference video recordings and slides at a discounted rate”. The HotChips slides are online (paywall) at IEEE website.

Fig. 7. A photograph of Dr. Dharmendra Modha, IBM Fellow, giving a talk on NorthPole.
Fig. 8. A photograph of Dr. Dharmendra Modha, IBM Fellow, giving a talk on NorthPole.
§F. History & Context:
In 2004, nineteen years ago, I had a stark realization that I was going to die — not imminently, but eventually. Therefore, 7,034 days ago, on July 16, 2004, I decided to focus my life’s limited energy on brain-inspired computing — a career wager against improbable odds. Along the way, we carried out simulations at the scale of mouse, rat, cat, monkey, and, eventually, human brains — winning ACM’s Gordon Bell Prize along the way. We mapped (Link: https://www.pnas.org/doi/10.1073/pnas.1008054107) the long-distance wiring diagram of the primate brain. TrueNorth won the inaugural Misha Mahowald Prize and is in the Computer History Museum. I was named R&D Magazine’s Scientist of the Year, became an IBM Fellow, was named Distinguished Alumni of IIT Bombay, and was named Distinguished Alumni of UCSD ECE Department. The project has been featured on the covers of Scientific American, Science (twice), and Communications of the ACM.
The first idea for NorthPole was conceived on May 30, 2015, in a flash of meditative insight, at Crissy Field in San Francisco. The main motivation was to dramatically reduce capital cost of TrueNorth. Over the next few years, collaboratively and creatively, we pushed boundaries of innovation along all aspects of computation, memory, communication, control, and IO. Starting in 2018, we went under stealth mode. To focus fully on NorthPole, we turned down all talk invitations and we stopped the flow of publications, taking a huge risk. Along the way, the project encountered many technical, economic, and political obstacles and nearly died many times — not even counting the pandemic. The unique combination of the environment of IBM Research and the long-term support of DoD was the key to forward progress. So, TrueNorth and NorthPole are a story of seeking long-term rewards, a tale of epic collaborations, an example of team creativity (Link: https://www.nytimes.com/2013/10/13/jobs/when-debate-stalls-try-your-paintbrush.html), an account of perseverance and steadfastness of purpose, and a chronicle of a vision realized. To quote General Leslie Groves, who directed the Manhattan project, “now it can be told.”
TrueNorth was a direction, NorthPole is a destination.
Although we have been working on it for 19 years, this moment can be best described by quoting Winston Churchill: “Now this is not the end. It is not even the beginning of the end. But it is, perhaps, the end of the beginning.”
§G. Applications and Systems:
NorthPole is suitable for classification, detection, segmentation, video classification, speech recognition, and transformers (see Tables S7-S12 in the supporting online material). Neural networks that exceed the on-chip memory requirements of a single NorthPole chip, for example, large language models such as Mistral-7B, Llama2-7B, and Llama2-13B, can be partitioned across multiple NorthPole chips via scale-out.

Fig. 9. Photograph of assembled NorthPole PCIe printed circuit board (Research Prototype).

Fig. 10. Single NorthPole assembly in a 1U server (Research Prototype).

Fig. 11. Four NorthPole assemblies in a server (Research Prototype).
8, 10, 12, 16 assemblies in a server are possible.
§H. Essence of innovation:
We took from the brain: modularity of cores, tileability of cores, massive parallelism, simple compute with 8-, 4-, 2-bits of precision, nearness of compute and memory, network-on-chip based on long-distance white matter pathways, network-on-chip based on short-distance gray matter pathways, enabling spatial computing, lack of off-chip memory, and lack of centralized memory. However, the brain is built from an organic substrate (technology). The brain’s organic biochemical substrate is suitable for supporting many, slow, analog neurons, where each neuron is hard-wired to a fixed set of synaptic weights. Directly following this architectural construct leads to an inefficient use of inorganic silicon that is suitable for fewer, faster, digital neurons. To balance brain-inspired architecture with silicon, we introduced reconfigurability that resolves this key dilemma by storing weights and programs just once in the distributed memory and reconfiguring the weights via one network-on-chip and reconfiguring the programs via another network-on-chip.
NorthPole innovates on all dimensions of compute, memory, communication, control, and IO.
NorthPole merges the boundaries between brain-inspired computing and silicon-optimized computing, between compute and memory, between hardware and software, between distributed cores and integrated cores, and between 2-bit to 4-bit to 8-bit precision.
Interestingly, seen from inside the chip, at the level of individual cores, NorthPole appears as memory-near-compute and, seen from outside the chip, at the level of input-output, it appears as an active memory.
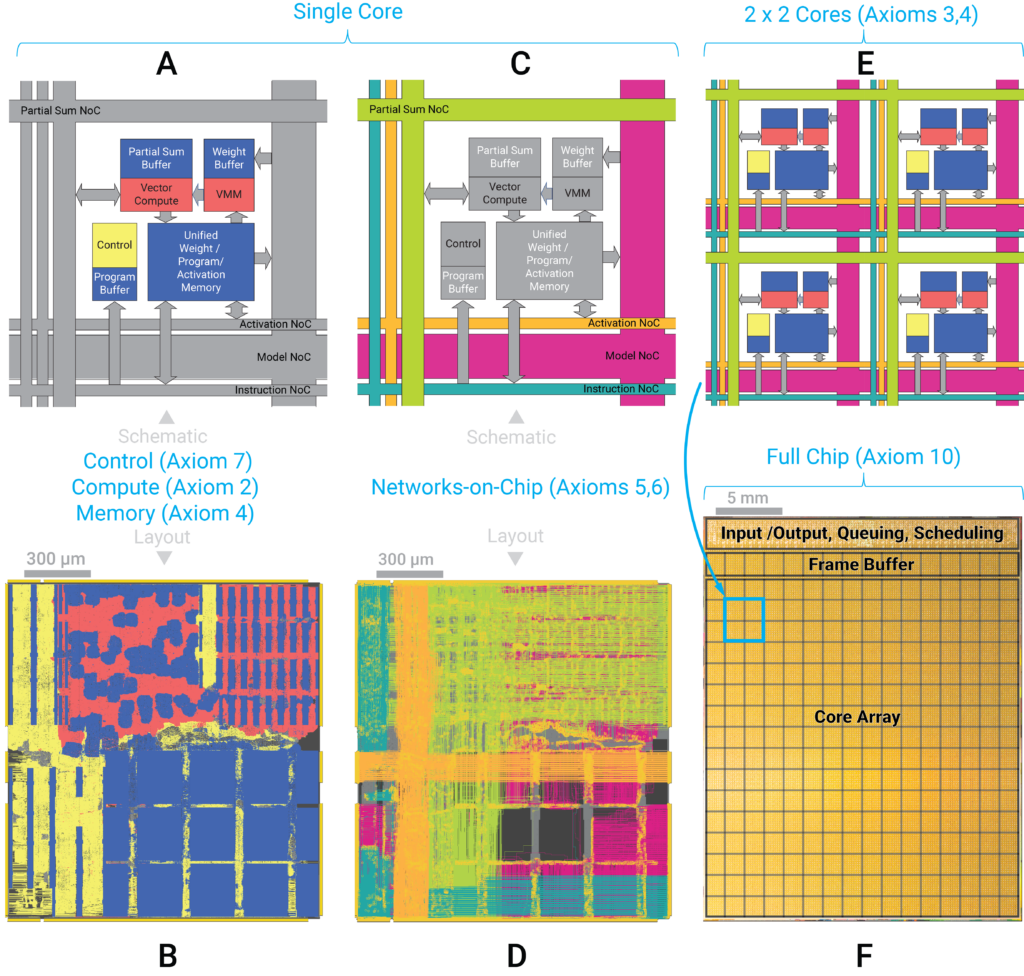
Fig. 12. NorthPole axiomatic architecture and implementation (Figure 2 in the Science paper).
§I. Implementation:
NorthPole:
- has been fabricated in a 12nm process on-shore in US
- has 22 billion transistors in an 800 square-millimeter area
- has 256 cores; has 2,048 (4,096 and 8,192) operations per core per cycle at 8-bit (at 4-bit and 2-bit, respectively) precision
- has 224MB of on-chip memory (192MB in core array, 32MB framebuffer for input-output)
- has over 4,096 wires crossing each core both horizontally and vertically
- has 2,048 threads
- is fully operational in first silicon implementation
- is currently deployed in a PCIe form factor research prototype printed circuit board

Fig. 13. Image of the assembled NorthPole laminate. The image is a composite of a photograph of an actual laminate with the die photograph of IMAGE_01 overlaid (normally the gold side faces down and is bonded to the laminate.)
§J. Useability:
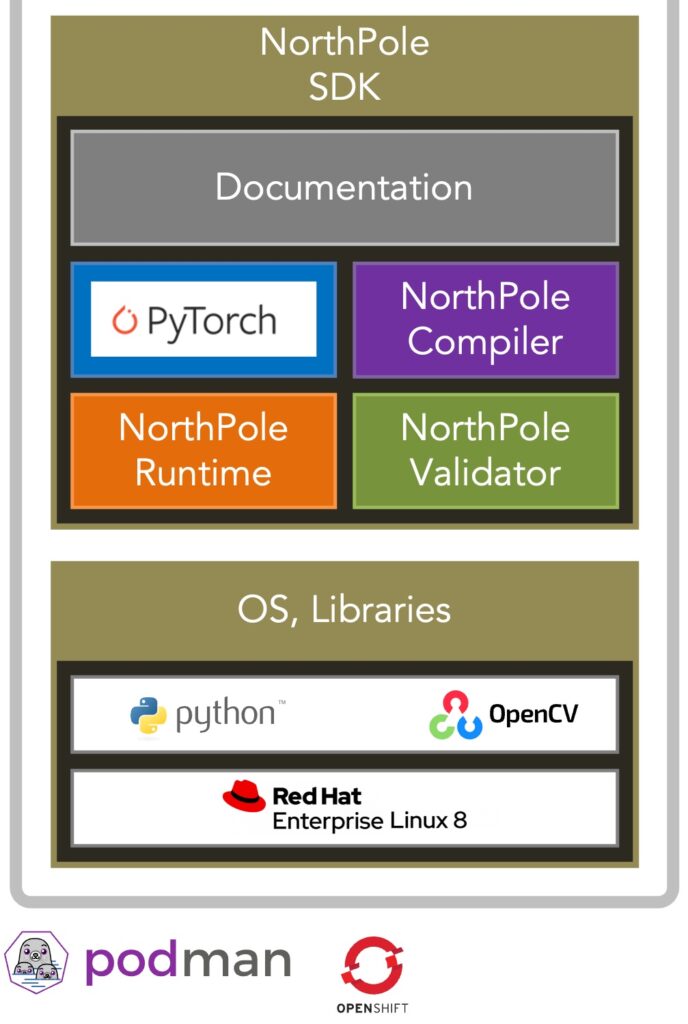
Fig. 14. NorthPole has an end-to-end containerized toolchain (Research Prototype).
Using the toolchain and the NorthPole boards/systems, we have conducted a number of workshops on teaching developers on using NorthPole for their applications.

Fig. 15. Developer Workshop on August 8-9, 2023.

Fig. 16. Early adopters.

Fig. 17. IBM team at the workshop.
§K. Technical summary:
NorthPole
… is specialized to inference
… performs at the frontier of energy, space, and time
… can support many deep networks in vision, speech, and natural language
… has brain-inspired and silicon-optimized architecture
… has modular, tileable architecture – like the cortex
… has massive parallelism – like the cortex
… has mixed-precision – like the cortex
… has memory-near-compute – like the cortex
… has no off-chip requirement, has no centralized memory, and has no von Neumann bottleneck – like the cortex
… has only three commands: write tensor(s), run network, read tensor(s) – is an active memory
… has minimum IO bandwidth requirement
… has minimum load on the host
… has two dense brain-inspired networks-on-chip
… has two dense silicon-optimized networks-on-chip
… has no VLIW
… has pre-scheduled, deterministic operation in the core array free from cache-misses
… has unscheduled, input-driven operation in the framebuffer for queuing and isolation
… has co-designed mixed-precision training algorithms
… has an end-to-end software toolchain
… has a current PCIe implementation with many possible custom boards
… has an easy scale-out implementation
… has significant headroom in terms of system scaling, silicon scaling, architecture innovations
§L. Six word stories from some of the authors:
Dharmendra S. Modha: “Whole >>> sum of the team,” “Universe is cold, rare hot pockets,” “Thermodynamics’s second law, fight every moment,” “brain’s architecture, semiconductor physics, NorthPole bridges,” “organic brain, inorganic silicon — incompatibility resolved,” “distribute memories unified via networks on-chip”, “low energy, less space, faster response,” “lower OpEx, lower CapEx, lower latency,” “TrueNorth – a direction; NorthPole – a destination,” and, finally, “Inorganic Brain-inspired Machine — decode the message!”
Alexander Andreopoulos: “Designed and built in the U.S.”
John V. Arthur: “Local memory, low power, high performance.”
Andrew S. Cassidy: “Defining the new frontier of compute” and “Expanding computational frontiers: space, energy, time.”
Jun Sawada: “Low power, mixed precision, high throughput.”
Deepika Bablani: “Where the brain meets the wafer”
Jeffrey A. Kusnitz: “NorthPole isn’t just for Santa anymore” and “Eight very long years later, NorthPole.”
Daniel F. Smith: “Clustered silicon neurons are efficiently zippy.”

Fig. 18. Authors of the Science paper.
§M. Funding: This material is based upon work supported by the United States Air Force under Contract No. FA8750-19-C-1518. Support from OUSD(R&E) is gratefully acknowledged.
§N. Thanks:
Thank you to my co-authors: Filipp Akopyan, Alexander Andreopoulos, Rathinakumar Appuswamy, John Arthur, Andrew Cassidy, Pallab Datta, Michael DeBole, Steve Esser, Carlos Tadeo Ortega Otero, Jun Sawada, Brian Taba, Arnon Amir, Deepika Bablani, Peter Carlson, Myron Flickner, Rajamohan Gandhasri, Guillaume Garreau, Megumi Ito, Jennifer Klamo, Jeff Kusnitz, Nathaniel McClatchey, Jeffrey McKinstry, Yutaka Nakamura, Tapan Kumar Nayak, William Risk, Kai Schleupen, Ph.D. EE, Ben Shaw, Jay Sivagnaname, Daniel F Smith, Ignacio Terrizzano, Takanori Ueda.
Thank you to the US Government for vision, leadership, support, and collaboration over 14 years from United States Department of Defense, Office of the Under Secretary of Defense for Research and Engineering, Air Force Research Laboratory, Defense Advanced Research Projects Agency (DARPA), and U.S. Department of Energy (DOE): Hon. Heidi Shyu, Maynard Holliday, Dev Shenoy, Qing Wu, Kristen Baldwin, Richard Linderman, Todd Hylton, Zachary J. Lemnios, Gill Pratt, Jay Schnitzer, Mark Barnell, Matt Klaric, Barbara McQuiston, Ramesh Menon, Brian Van Essen, Tony Tether, Jeremy Muldavin.
Thank you to IBM and IBM Research Management: Jeffrey Welser, Dario Gil, John E Kelly III, Arvind Krishna, Ginni Rometty. Special thanks to Arvind Krishna for supporting the NorthPole grand challenge from 2015-2018 and thanks to Mark Dean for supporting the original grand challenge in 2006-2008.
Thank you to my alma maters: UC San Diego, UC San Diego Electrical and Computer Engineering, Indian Institute of Technology, Bombay.
Thank you to past collaborators: Rajit Manohar, Paul Merolla, Raghavendra Singh, and Horst Simon.
Thank you to my mentors and teachers: Norm Pass, Moshe Vardi, Larry Smarr, Ramesh Rao, Julio M. Ottino, Jon Iwata, Elias Masry, Robert Hecht-Nielsen, Terry Sejnowski, Ken Kreutz-Delgado, and Bhaskar Rao, Jai Menon.
Thank you to many collaborators for NorthPole: Istak Ahmed, Thomas Amberg, Nicolas Antoine, Franklin Baez, Heinz J Baier, Layne Berge, Ramesh Bhimarao, Jason Bjorgaard, Mike Boraas, Bernard Brezzo, Matthew Butterbaugh, Eric J Campbell, Hari Chandran, Evan Colgan, Michael E Criscolo, Carmelo di Nolfo, Matthew Doyle, Mike Grassi, Christopher Guido, Darin Hitchings, Ryan Hoke, Kevin Holland, Sing-Sai Hui, Thomas Jones, Sugun Kedambadi, Panagiotis Kourdis, Andrea LaPiana, Giuseppe LaPiana, Jeremy Lee, Scott Lekuch, Zuolin Liu, Ranjit Loboprabhu, Arvind Lonkar, Ding Ma, Grady Maass, Sunil Machha, Venkatesh Mahadevan, Phillip V Mann, Michael Mastro, Neil McGlohon, Kevin O’Connell, Bakul Parikh, Hartmut Penner, Prashanth A. V. , Robert Purdy, Mayuresh Rajwadkar, Sitara Rajshekhar Rao, L. Rapp, Kenny Rice, Camillo Sassano, Jayashree Saxena, Kyle Schoneck, Ross Scouller, Jeffrey Shaffer, Deepesh Shukla, Anthony Sigler, Sam Skalicky, Chris Smallwood, Nikkitha Subbiah, Shurong Tian, Tim Tidwell, David Turnbull, Michael Uman, G. Van Leeuwen, Suren Vispute, Ivan Vo, Jonathan Wang , Charles Werner , Subhash Wundavilli, Chee Nou Xiong.
Thank you to the Anora Labs DFT team, and teams from Cadence Design Systems and GlobalFoundries (Ted Letavic, Mike Cadigan).
Thank you to my friends: Mayur Kapani, Anand Raman, Vijay Panchamia, Sanjay Kaluskar, Shalini Govil-Pai, Bharadwaj Amrutur, Bharat Shyam Shankar Krishnamoorthy, Devesh Khatu, Shiv Kaushik, Sanjeev Chhabra, Ajaykumar Kunnath, Ajay Sethi, Stephen Hamm, Nimrod Megiddo, and, of course, Anuradha Narasimhan.
§O. A continuing 19-year journey

Fig. 19. An info-graphic illustrating major milestones of a 19-year journey.
Note that since 2015, NorthPole has been in the stealth mode.
§P. FUN & CREATIVITY:
The following image was created in the spirit of fun and creativity.

Fig. 20. To illustrate the idea that NorthPole is a faint reflection of the brain in the mirror of silicon, my face is reflected in NorthPole. Photo: William Risk and concept by John Arthur.